RLAIF Research
PG Research Article for Statistical Natural Language Processing Module at UCL
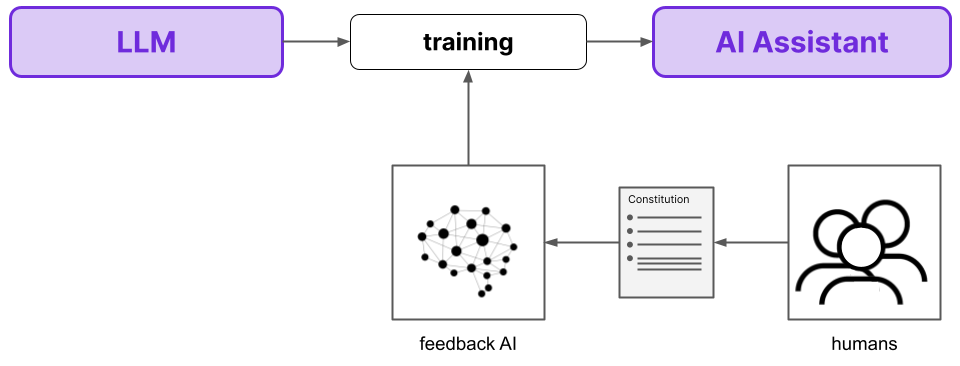
Explored the Reinforcement Learning with AI/Human Feedback (RLAIF/RLHF) paradigm, examining its application to align large language models with human preferences. The study compared various RLHF methods and implemented PPO (Proximal Policy Optimization) from scratch to better understand the complexities of human preference learning.